

In this article
- 🔍 We'll learn what semantic search is.
- 🎉 We'll discuss how semantic search impacts the user experience
- 🦀 We'll see the use case of a new npm library called Voy, a WASM vector similarity search engine written in Rust.
Let's go.
This article is also available on
Feel free to read it on your favorite platform✨
What Is Semantic Search?
Semantic search is a type of search that focuses on meanings. You can search with human language or vague concepts, and the search result will give you similar data points in the database based on the semantics of your search query.
It almost feels like semantic search engines "understand" the meaning of your questions. You can ask any question in your natural language like "Which Marvel movie to watch after Shang-Chi?". The engines understand the meaning and why you ask that question and it returns the most relevant results back to you.
In fact, semantic search engines commonly use pre-trained Neural Networks models to understand the search intent and contextual meanings, and generate a computational representation of the search queries and database. We often refer to the representation as "vector embeddings" or "embeddings". The engine will then classify the embeddings and find the nearest neighbors of the search query embeddings. The nearest neighbors are the data points that are the most relevant to what you're looking for.
To illustrate how semantic search works:
The image originated from Google Research's blog "Announcing ScaNN: Efficient Vector Similarity Search".
Who Uses Semantic Search?
Semantic search is everywhere. It's so valuable because it has a big impact on user experience:
- Users are able to search and access digital content in a more human way.
- Search engines are able to provide more relevant and helpful content to the users and make SEO strategy around keywords irrelevant.
- Search can be blazingly fast for big data.
- Search isn't limited to text anymore. We can create embeddings from different types of digital content, like images and videos.
Some examples of the major companies that integrated semantic search:
- Google: Hummingbird
- Amazon: Semantic product search
- Spotify: Natural Language Search
- Meta: Facebook AI Similarity Search
- Redis: Redis Vector Similarity Search
Introducing Voy
Voy is an open source semantic search engine in WebAssembly (WASM). I created it to empower more projects to build semantic features and create better user experience for people around the world. Voy follows several design principles:
- Tiny: Reduce overhead for limited devices, such as mobile browsers with slow network or IoT.
- ️ Fast: Create the best search experience for the users.
- 🌳 Tree Shakable: Optimize bundle size and enable asynchronous capabilities for modern Web API, such as Web Workers.
- 🔋 Resumable: Generate portable embeddings index anywhere, anytime.
- ☁️ Worldwide: Run semantic search on CDN edge servers.
It's available on npm. You can simply install it with your favorite package manager and start using it.
# with npm
npm i voy-search
# with Yarn
yarn add voy-search
# with pnpm
pnpm add voy-search
To demonstrate what it looks like:
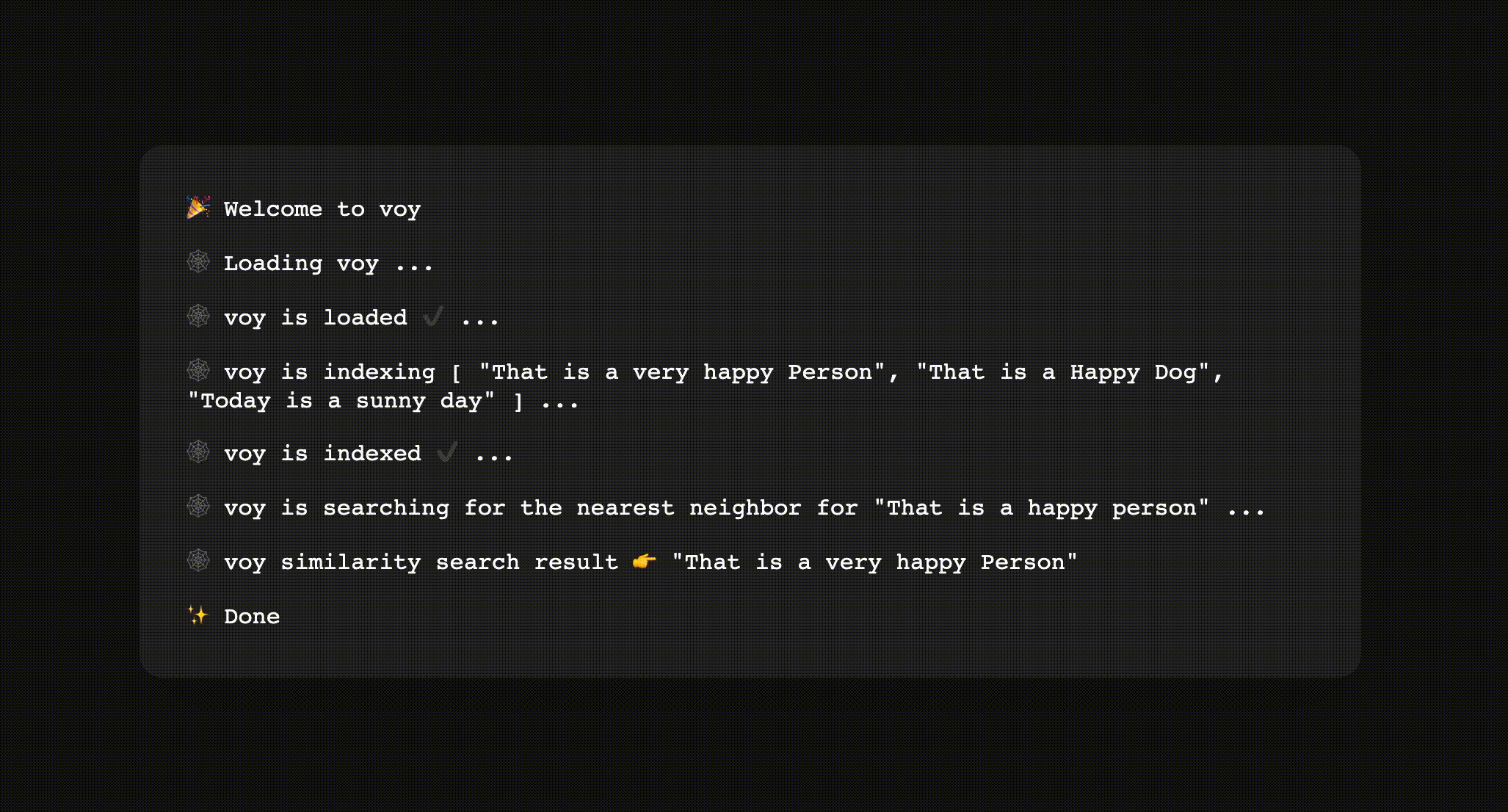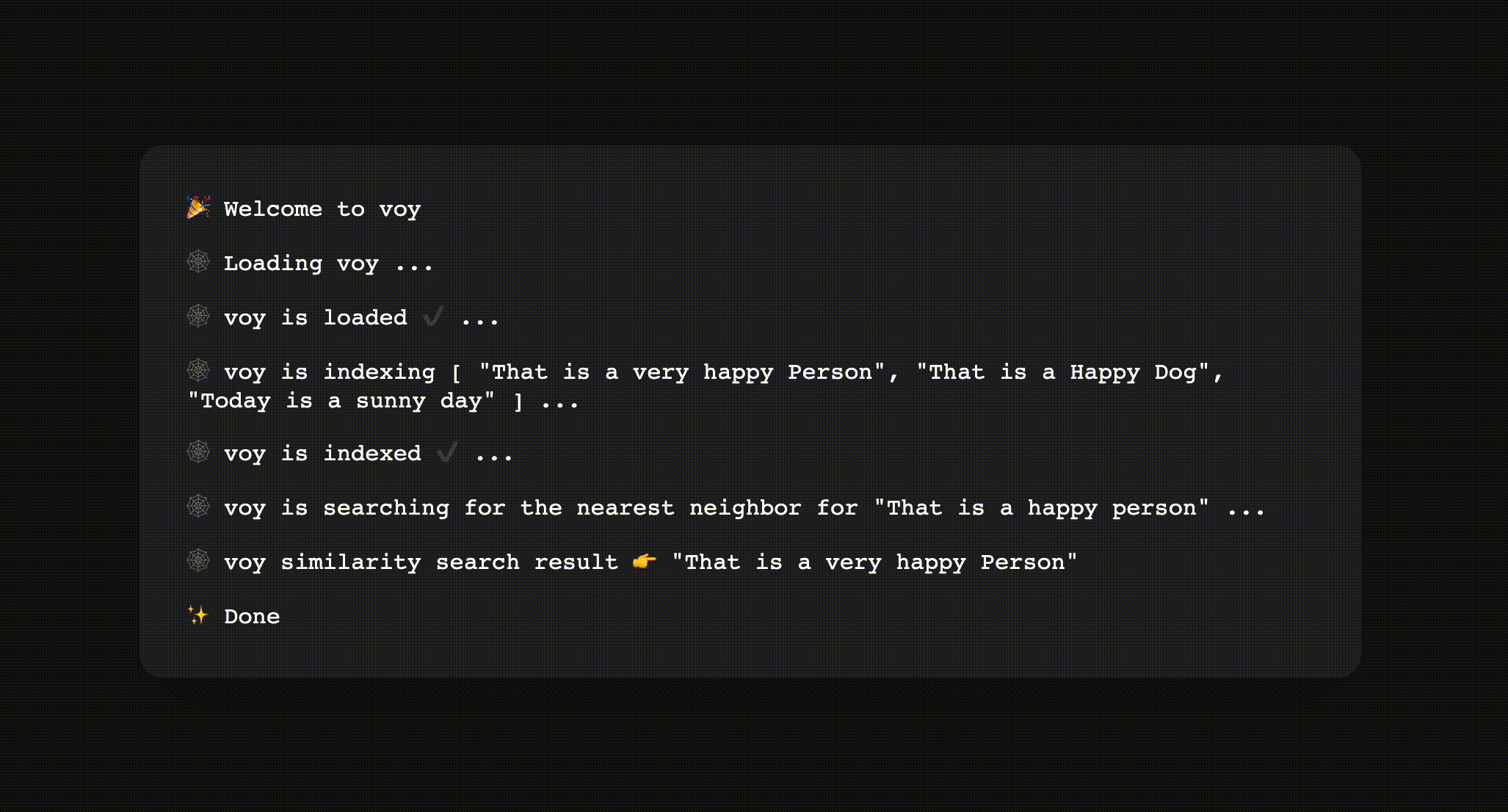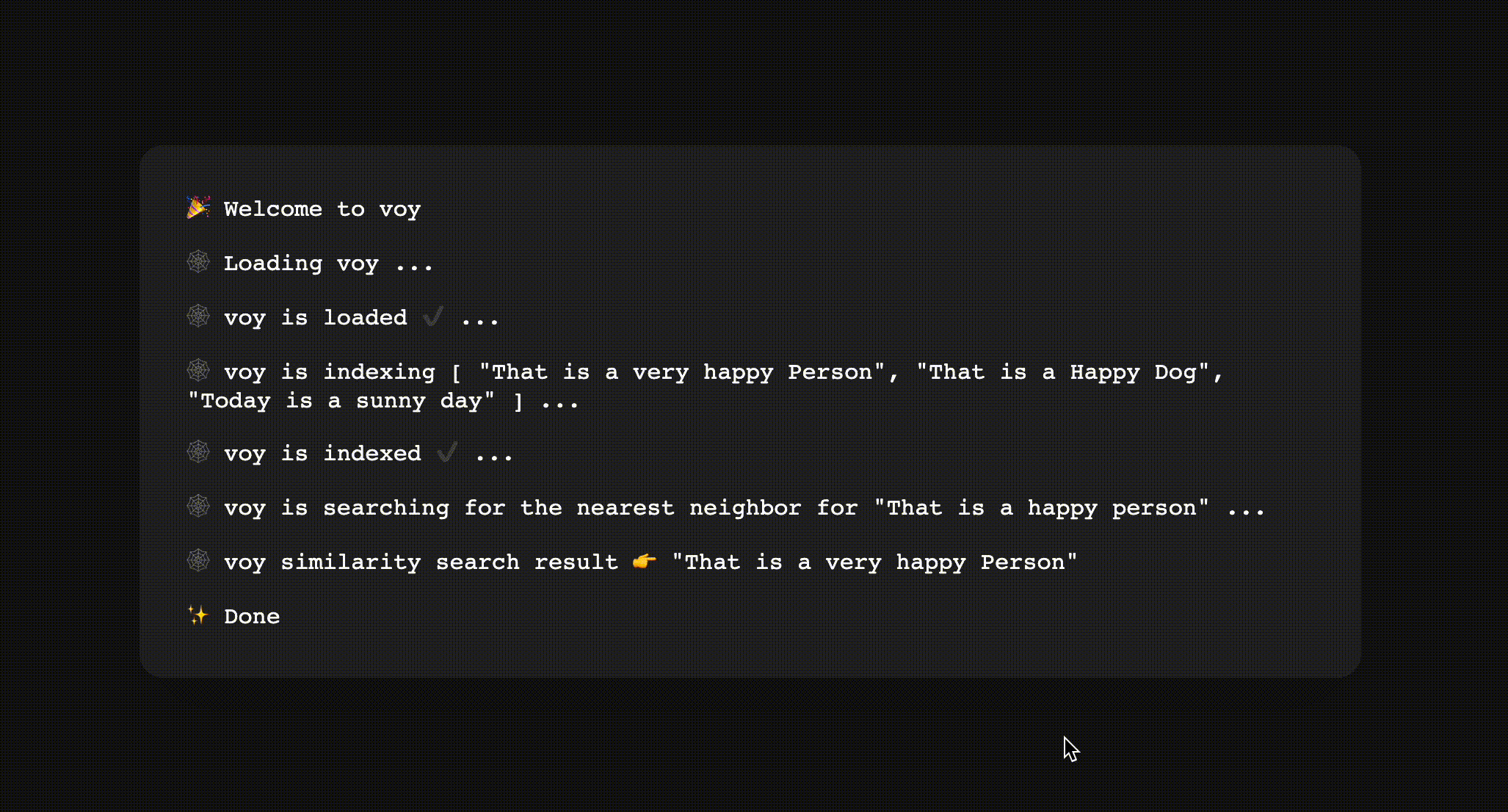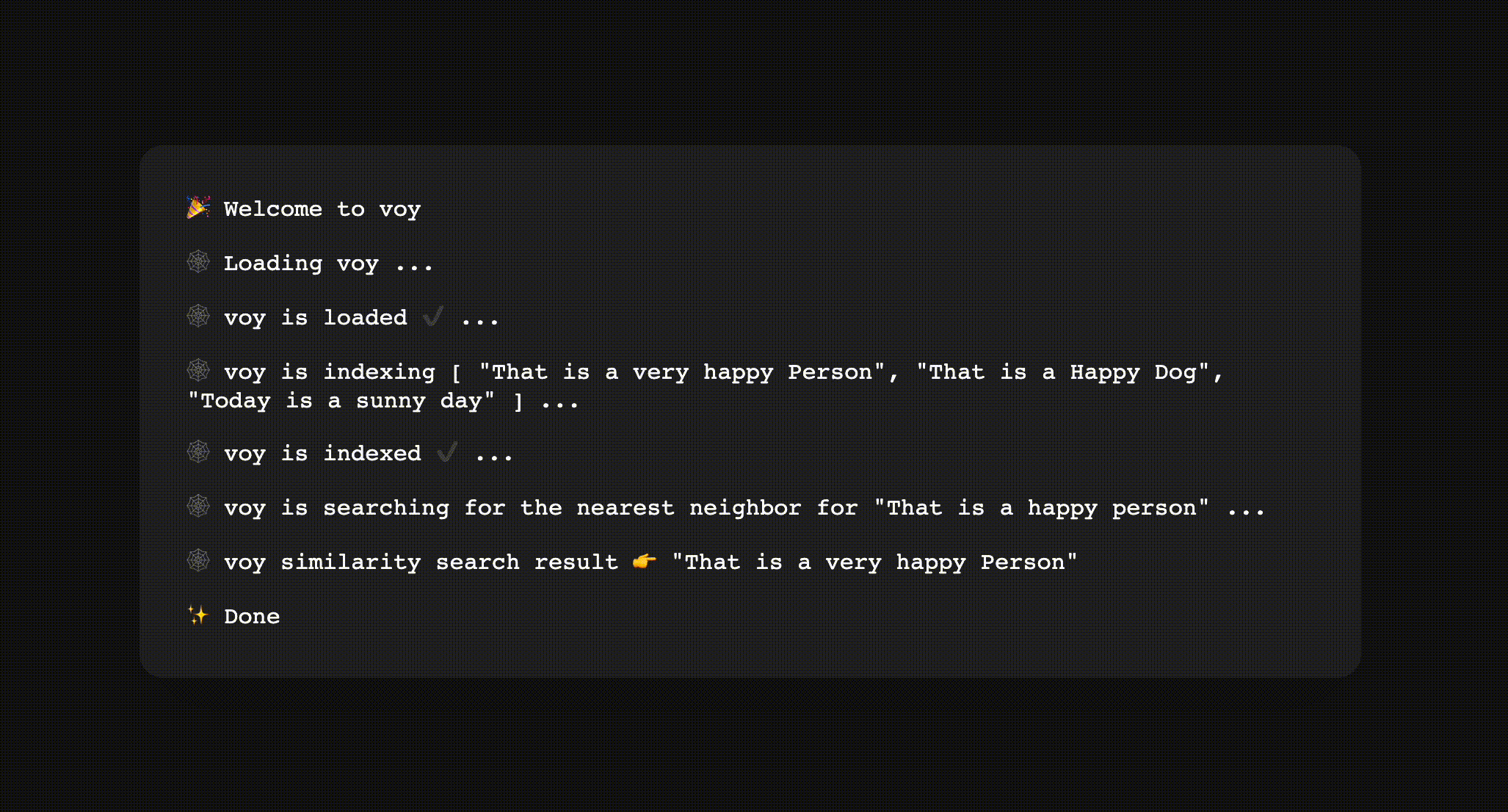
You can find the Voy's repository on GitHub! Feel free to try it out.
The repository includes an example where you can see how to load the WASM module with Webpack 5.
Let's break it down a bit to see what it did. First, the demo was loading the WASM module asynchronously. After loading, it started indexing the following phrases:
- "This is a very happy Person"
- "That is a Happy Dog"
- "Today is a sunny day"
Indexing is where we transforms the phrases into embeddings and organize them in a embedding space. Once the index was ready, the demo performed a similarity search with the phrase "That is a happy Person". Finally we saw the search result returns "This is a very happy Person" as the top result.
We can reason about the credibility of the result because "This is a happy Person" does have the highest semantic similarity to "This is a very happy Person".
How does Voy Work?
Voy takes care of two things:
- Indexing resources.
- Retrieving nearest neighbors from the index.
Index Resources
To demonstrate, we'll use "text" as our resource.
The embeddings are organized and stored in a k-d tree under the hood. k-d tree is a data structure for organizing data in a k-dimensional space. It is very useful for our vector embeddings index because the embeddings are fixed floating arrays.
As of now, packaging an embeddings transformers into WASM is still under development. So Voy relies on other libraries like Web AI to generate embeddings.
// Dynamically import Voy
const voy = await import('voy')
const phrases = [
'That is a very happy Person',
'That is a Happy Dog',
'Today is a sunny day',
]
// Use web-ai to create text embeddings
const model = await(await TextModel.create('gtr-t5-quant')).model
const processed = await Promise.all(phrases.map((q) => model.process(q)))
// Index embeddings with Voy
const data = processed.map(({ result }, i) => ({
id: String(i),
title: phrases[i],
url: `/path/${i}`, // link to your resource for the search result
embeddings: result,
}))
const index = voy.index({ embeddings: data }) // index is a serialized k-d tree
As you can see, after executing voy.index(), it returns a serialized index. It allows Voy to deserialize the index when executing searches without being in the same environment. For example, the index can be created in build time and ship the serialized index to the client to perform searches. It is referred as the resumability.
Retrieve Nearest Neighbors
// Create query embeddings
const query = await model.process('That is a happy Person')
// Search with Voy and return the 1 result
const nearests = voy.search(index, query.result, 1)
// Display vector similarity search result
nearests.forEach(
(result) => log(` voy similarity search result 👉 "${result.title}"`) // That is a very happy Person
)
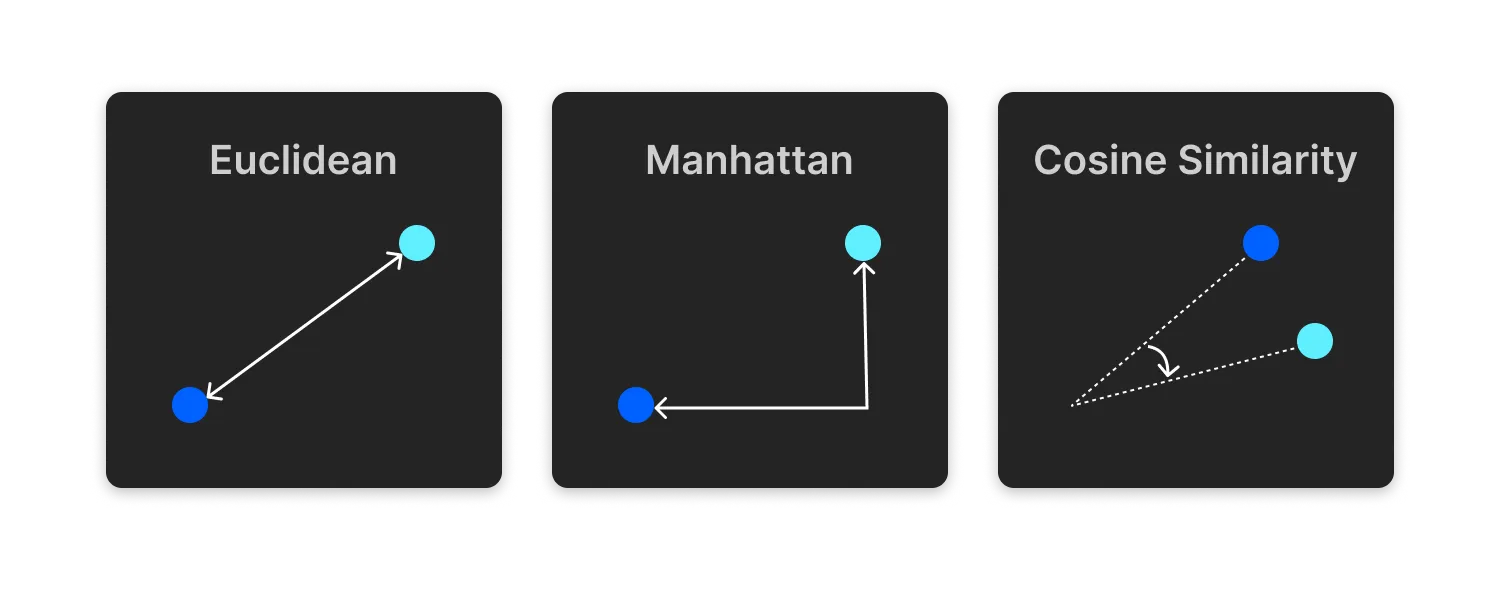
Internally, Voy uses Squared Euclidean distance to calculate the nearest neighbors. There're a few ways to calculate the distance between points. Here the points are the nodes of the embeddings object in the k-d tree. The common formulas are:
Final Thoughts
Voy is created to make semantic accessible for developers to build, ship, and create user value. It still has a few more steps to be a self-sufficient semantic search engine. If you're interested, you can follow Voy's public roadmap.
If you believe in Voy's mission and would like to support the project, please check out the sponsor section on the GitHub repository.
If you are interested in some of the open source embeddings transformers, here are some of the projects I experimented with:
- spotify/annoy
- facebookresearch/faiss
- google-research/bert
- UKPLab/sentence-transformers with the all-MiniLM-L12-v2 model
References
- Announcing ScaNN: Efficient Vector Similarity Search - Google Research
- Build Intelligent Apps with New Redis Vector Similarity Search - Redis
- Cosine similarity - Wikipedia
- Euclidean distance - Wikipedia
- facebookresearch/faiss - GitHub
- Faiss: A library for efficient similarity search - Engineering at Meta
- Find anything blazingly fast with Google's vector search technology - Google Cloud
- Google Hummingbird - Wikipedia
- google-research/bert - GitHub
- I Built A Snappy Static Full-text Search with WebAssembly, Rust, Next.js, and Xor Filters - Daw-Chih Liou
- Introducing Natural Language Search for Podcast Episodes - Spotify
- k-d tree - Wikipedia
- Manhattan distance - Wikipedia
- Nearest neighbor search - Wikipedia
- Neural network - Wikipedia
- Semantic product search - Amazon Science
- Semantic search - Wikipedia
- sentence-transformers/all-MiniLM-L12-v2 - Hugging Face
- Similarity search - Wikipedia
- spotify/annoy - GitHub
- tantaraio/voy - GitHub
- UKPLab/sentence-transformers - GitHub
- visheratin/web-ai - GitHub
- Voy Roadmap - GitHub Projects
- What is semantic search: A deep dive into entity-based search - Search Engine Land
- WebAssembly - W3C Community Group
- Web Workers API - mdn web docs
- Webpack - OpenJS Foundation
💬 Comments on Reddit.
Here you have it! Thanks for reading through🙌 If you find this article useful, please share it to help more people in their engineering journey.
🐦 Feel free to connect with me on twitter!
Ready for the next article? 👉 Lean Docker Images for Next.JS
Happy coding!