

TL;DR
- 🦀 There is a rich toolkit for developing WebAssembly with Rust. It's fun!
- 🤝 WebAssembly and Next.js play fairly well together, but be aware of the known issues.
- 🔬 Xor filters are data structures that provides great memory efficiency and fast lookup for value existence.
- 🍳 WebAssembly's performance and code size is not guaranteed. Make sure to measure and benchmark.
This article is also available on
Feel free to read it on your favorite platform✨
I always knew I wanted a full-text search feature for the articles in my portfolio to provide the visitors with a quick access to the content they are interested in. After migrating to Contentlayer, it doesn't seemed to be so far-fetched anymore. So I started exploring🚀
Inspired by tinysearch: A WebAssembly Full-text Search Engine
After some researching, I found a search engine called tinysearch. It's a static search engine built with Rust and WebAssembly (Wasm). The author Matthias Endler wrote an amazing blog post about how tinysearch came about.
I loved the idea of constructing a minimalistic search engine at build time and shipping it in optimized low-level code to the browsers. So I decided to use tinysearch as the blueprint and write my own search engine to integrate with my Next.js static site.
I highly recommend reading tinysearch's codebase. It's very well-written. My search engine's implementation is a simplified version of it. The core logic is the same.
What Does The Search Feature Looks Like?
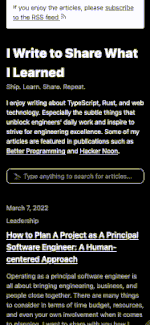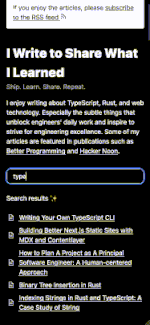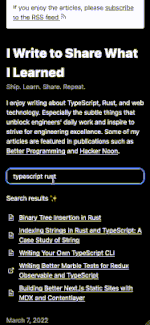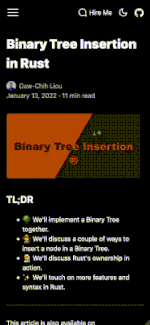
Very simple:
- Users type anything in the search input.
- Search engine searches the key words in all the contents and finds the most relevant articles.
- UI displays a ranked search result list.
You can try out the search function at the Articles page!
A Little Bit of Stats
At the time of writing this article, there are:
- 7 articles (more to come🚀)
- 13,925 words
- 682KB of data files (generated by Contentlayer)
For the full-text search to work for static sites that are priming for speed, the code size has to be small.
How Does WebAssembly Full-text Search Function Work?
Most of the modern browsers now support WebAssembly. They are able to run native WebAssembly code and binary alongside JavaScript.
The concept for the search function is straightforward. It takes in a query string as parameter. In the function, we tokenize the query into search terms. We then give a ranking score to each article based on how many search terms does it contain. Finally, we rank the articles by relevancy. The higher the score, the more relevant it is.
The flow looks like this:
+--------------+ +--------------+
| | | |
| Query String | - tokenize -> | Search Terms |
| | | |
+--------------+ +--------------+
|
+--------------+ | +-----------------------+ +-----------------------+ +--------------+
| | | | | | | | |
| Vec<Article> | ------------------ score -> | Vec<(Article, Score)> | - rank -> | Vec<(Article, Score)> | - take(n) -> | Vec<Article> |
| | | | | | | |
+--------------+ +-----------------------+ +-----------------------+ +--------------+
Scoring the articles is where the most computing comes in. A naive approach would be transforming each article into a hash set that contains all the unique words in the article. We can calculate the score by simply counting how many search terms are in the hash set.
You can image that this is not the most memory efficient approach with hash set. There are better data structures to replace it: xor filters.
What are Xor Filters?
Xor filters are relatively new data structures that allow us to estimate whether a value exists or not. It's fast and memory efficient so it's very suitable for the full-text search.
Instead of storing the actual input values like hash set, xor filters store fingerprints (L-bit hashed sequence) of input values in a specific way. When looking for whether a value exists in the filter, it checks if the fingerprint of the value is present.
However, Xor filters have a couple of trade-offs:
- Xor filters are probabilistic and there's a chance false-positive can happen.
- Xor filters are not able to estimate the existence of partial values. So in my use case, the full-text search will only be able to search for complete words.
How Did I Build the Xor Filters with Rust?
Since I had the article data generated by Contentlayer, I constructed the xor filters by feeding them with the data before the WebAssembly is built. I then serialized the xor filters and stored them in a file. To use the filters in the WebAssembly, all I needed to do was to read from the storage file and deserialize the filters.
The filter generation flow looks like this:
+-------------------+ +---------------+ +----------------------------+ +-------------+
| | | | | | | |
| Contentlayer Data | - generate -> | Article Index | - construct -> | Vec<(Article, Xor Filter)> | - serialize -> | storage.txt |
| | | | | | | |
+-------------------+ +---------------+ +----------------------------+ +-------------+
xorf crate is a good choice for xor filters implementation because it offers serialization/deserialization and a few features that improve memory efficiency and false-positive rate. It also provides a very handy HashProxy struct for my use case to construct a xor filter with a slice of strings. The construction written in Rust roughly look like this:
use std::collections::hash_map::DefaultHasher;
use xorf::{Filter, HashProxy, Xor8};
mod utils;
fn build_filter(title: String, body: String) -> HashProxy<String, DefaultHasher, Xor8> {
let title_tokens: HashSet<String> = utils::tokenize(&title);
let body_tokens: HashSet<String> = utils::tokenize(&body);
let tokens: Vec<String> = body_tokens.union(&title_tokens).cloned().collect();
HashProxy::from(&tokens)
}
If you are interested in the actual implementation, you can read more in the repository.
Putting It All Together
👾Build-Time Run-Time
+-------------------+ +------------+
| Contentlayer Data | | User Input |
+-------------------+ +------------+
| |
generate call wasm.search(query)
| |
+---------------+ +---------------+
| Article Index | | Query String |
+---------------+ +---------------+
| |
construct tokenize
| |
+----------------------------+ +--------------+
| Vec<(Article, Xor Filter)> | | Search Terms |
+----------------------------+ +--------------+
| |
serialize |
| |
+-------------+ |
| storage.txt | - deserialize ------> score
+-------------+ |
+-----------------------+
| Vec<(Article, Score)> |
+-----------------------+
|
rank
|
+-----------------------+
| Vec<(Article, Score)> |
+-----------------------+
|
take(n)
|
+--------------+
| Vec<Article> |
+--------------+
|
return
|
+--------------+
| Vec<Article> |
+--------------+
|
display
|
+---------------+
| Search Result |
+---------------+
Integrating WebAssembly in Next.js
Here's how I integrated the xor filter generation script and WebAssembly inside Next.js.
The file structure looks like this:
my-portfolio
├── next.config.js
├── pages
├── scripts
│ └── fulltext-search
├── components
│ └── Search.tsx
└── wasm
└── fulltext-search
To support WebAssembly, I updated my Webpack configuration to load WebAssembly modules as async modules. To make it work for static site generation, I needed a workaround to generate the WebAssembly module in .next/server directory so that the static pages can pre-render successfully when running the next build script.
webpack: function (config, { isServer }) {
// it makes a WebAssembly modules async modules
config.experiments = { asyncWebAssembly: true }
// generate wasm module in ".next/server" for ssr & ssg
if (isServer) {
config.output.webassemblyModuleFilename =
'./../static/wasm/[modulehash].wasm'
} else {
config.output.webassemblyModuleFilename = 'static/wasm/[modulehash].wasm'
}
return config
},
That's all there is for the integration✨
Using The WebAssembly in The React Component
To build the WebAssembly module from the Rust code, I use wasm-pack.
The generated .wasm file and the glue code for JavaScript are located in wasm/fulltext-search/pkg. All I needed to do was to use next/dynamic to dynamically import the them. Like this:
import React, { useState, useCallback, ChangeEvent, useEffect } from 'react'
import dynamic from 'next/dynamic'
type Title = string;
type Url = string;
type SearchResult = [Title, Url][];
const Search = dynamic({
loader: async () => {
const wasm = await import('../../wasm/fulltext-search/pkg')
return () => {
const [term, setTerm] = useState('')
const [results, setResults] = useState<SearchResult>([])
const onChange = useCallback((e: ChangeEvent<HTMLInputElement>) => {
setTerm(e.target.value)
}, [])
useEffect(() => {
const pending = wasm.search(term, 5)
setResults(pending)
}, [term])
return (
<div>
<input
value={term}
onChange={onChange}
placeholder="🔭 search..."
/>
{results.map(([title, url]) => (
<a key={url} href={url}>{title}</a>
))}
</div>
)
}
},
})
export default Search
Optimizing The WebAssembly Code Size
Without any optimization, the original Wasm file size was 114.56KB. I used Twiggy to find out the code size.
Shallow Bytes │ Shallow % │ Item
───────────────┼───────────┼─────────────────────
117314 ┊ 100.00% ┊ Σ [1670 Total Rows]
Compared with the 628KB of raw data files, it was so much smaller than I expected. I was happy to ship it to the production already but I was curious to see how much code size I could trim off with The Rust And WebAssembly Working Group's optimization recommendation.
The first experiment was toggling LTO and trying out different opt-levels. The following configuration yields the smallest .wasm code size:
[profile.release]
+ opt-level = 's'
+ lto = true
Shallow Bytes │ Shallow % │ Item
───────────────┼───────────┼─────────────────────
111319 ┊ 100.00% ┊ Σ [1604 Total Rows]
Next I replaced the default allocator with wee_alloc.
+ #[global_allocator]
+ static ALLOC: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT;
Shallow Bytes │ Shallow % │ Item
───────────────┼───────────┼─────────────────────
100483 ┊ 100.00% ┊ Σ [1625 Total Rows]
Then I tried the wasm-opt tool in Binaryen.
wasm-opt -Oz -o wasm/fulltext-search/pkg/fulltext_search_core_bg.wasm wasm/fulltext-search/pkg/fulltext_search_core_bg.wasm
Shallow Bytes │ Shallow % │ Item
───────────────┼───────────┼─────────────────────
100390 ┊ 100.00% ┊ Σ [1625 Total Rows]
That's a 14.4% off from the original code size.
At the end, I was able to ship a full-text search engine in:
- 98.04 KB raw
- 45.92 KB gzipped
Not bad😎
Is It Really Snappy?
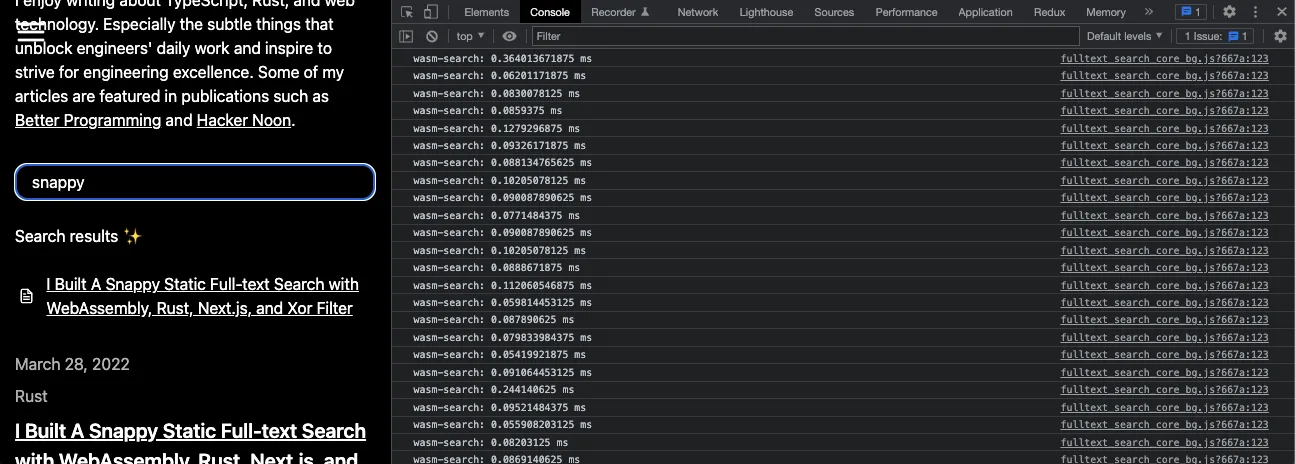
I profiled the performance with web-sys and collected some data:
- number of searches: 208
- min: 0.046 ms
- max: 0.814 ms
- mean: 0.0994 ms ✨
- standard deviation: 0.0678
On average, it takes less than 0.1 ms to perform a full-text search.
It's pretty snappy😎
Final Thoughts
After some experiment, I was able to build a fast and lightweight full-text search with WebAssembly, Rust, and xor filters. It integrates well with Next.js and static site generation.
The speed and size come with a few trade-offs but they don't have a big impact on the user experience. If you are looking for a more comprehensive search functionality, here are a few cool products available:
SaaS Search Engines
Static Search Engines
Server-based Search Engines
In-browser Search Engines
References
- Article: A Tiny, Static, Full-Text Search Engine using Rust and WebAssembly - Matthias Endler
- Article: Writing a full-text search engine using Bloom filters - Stavros Korokithakis
- Article: Xor Filters: Faster and Smaller Than Bloom Filters - Daniel Lemire
- Article: Shrinking .wasm Code Size - The Rust and WebAssembly Working Group
- Article: Building Better Next.js Static Sites with MDX and Contentlayer - Daw-Chih Liou
- Article: Next.js - Dynamic Import
- Website: Xor Filters: Faster and Smaller Than Bloom and Cuckoo Filters
- Website: Daw-Chih Liou's Portfolio
- Website: Meilisearch
- Website: Typesense
- Website: Algolia
- Website: Elasticlunr.js
- Website: Rust
- Website: WebAssembly
- Website: MDN WebAssembly
- Website: Next.js
- Website: Can I use WebAssembly?
- Lecture: Approximate Membership Queries - Stanford
- Wiki: Full-text Search
- GitHub: Next.js & WebAssembly example
- GitHub: Minimizing Rust Binary Size
- GitHub: dawchihliou.github.io
- GitHub: Webpack 5 breaks dynamic wasm import for SSR
- Github: tinysearch
- GitHub: Meilisearch
- GitHub: xorf
- GitHub: wasm-pack
- GitHub: Binaryen
- GitHub: Twiggy
- GitHub: Clippy
- GitHub: web-sys
- GitHub: once_cell
- GitHub: Bincode
- GitHub: wee_alloc
- GitHub: Serde
- GitHub: Anyhow
- GitHub: Contentlayer
- GitHub: FlexSearch
- GitHub: MiniSearch
Here you have it! Thanks for reading through🙌 If you find this article useful, please share it to help more people in their engineering journey.
🐦 Feel free to connect with me on twitter!
⏭ Read the next article: How to Plan A Project as A Principal Software Engineer: A Human-centered Approach
Happy coding!