

In this article
- 🙈 You'll learn what contributes to BigQuery's costs.
- We'll dive into BigQuery's architecture.
- 💰 You'll learn 3 easy steps to save 99.97% on your next Google Cloud bill.
Let's go.
This article is also available on
Feel free to read it on your favorite platform✨
How Did It Happen?
I was developing a script to prepare data samples for customers that reached out for consultations. The samples have 100 rows in each file and they are split in 55 locales. My query looks like this
SELECT *
FROM `project.dataset.table`
WHERE
ts BETWEEN TIMESTAMP("2022-12-01") AND TIMESTAMP("2023-02-28")
AND locale = "US"
LIMIT 100;
The data was stored in "europe-west-4" and the pricing for querying is $6 per TB. So by running the script, I processed
- 500 TB of data in total
- 3 TB of data per country on average
- $54 per data sample file on average
Very expensive.
The Script that Costed $3,000
The script was written in JavaScript modules.
import { BigQuery } from "@google-cloud/bigquery";
import { Parser } from "@json2csv/plainjs";
import makeDir from "make-dir";
import { write } from "./write.mjs";
import { locales } from "./locales.mjs";
import { perf } from "./performance.mjs";
const q = (locale, start, end, limit) => `SELECT *
FROM \`project.dataset.table\`
WHERE
ts BETWEEN TIMESTAMP("2022-12-01") AND TIMESTAMP("2023-02-28")
AND locale = "${locale}"
LIMIT ${limit}`
async function main() {
const timer = perf()
const dir = await makeDir('samples')
const bigquery = new BigQuery()
const csvParser = new Parser({})
try {
const jobs = locales.map((locale) => async () => {
// get query result from BigQuery
const [job] = await bigquery.createQueryJob({
query: q(locale, "2022-12-01", "2023-02-28", 100),
})
const [rows] = await job.getQueryResults()
// parse rows into csv format
const csv = parse(csvParser, rows)
// write data into csv files and store in the file system
await write(csv, dir, locale, "2022-12-01", "2023-02-28", 100)
})
await Promise.all(jobs.map((job) => job()))
console.log(`✨ Done in ${timer.stop()} seconds.`)
} catch (error) {
console.error('❌ Failed to create sample file', error)
}
}
await main()
It generates one sample file in CSV format per locale. The process is straightforward:
- Querying the BigQuery table with a local, start date, end date, and limit.
- Transforming the query result into CSV format.
- Writing the CSV in the file system.
- Repeating the process for all locales.
What's The Problem?
It turns out that I did several things wrong in my query. If you look at the pricing model again, you'll notice the cost is only related to how much data you process. So it's clear that my query looked up too much data to produce 100 rows. With this insight, let's optimize the query step by step.
Don't Select *
It's a little counter intuitive. Why does my select statement have anything to do with how much data it processes? Regardless of the columns I select, I should be reading from the same resources and data, right?
It's only true for row-oriented databases.
BigQuery is actually a columnar database. It's column-oriented, meaning the data are structured in columns. BigQuery uses Dremel as its underlying computing engine. When the data is moved from the cold storage to the active storage in Dremel, it stores the data in a tree structure. Each leaf node is a column-oriented "record" in Protobuf format.
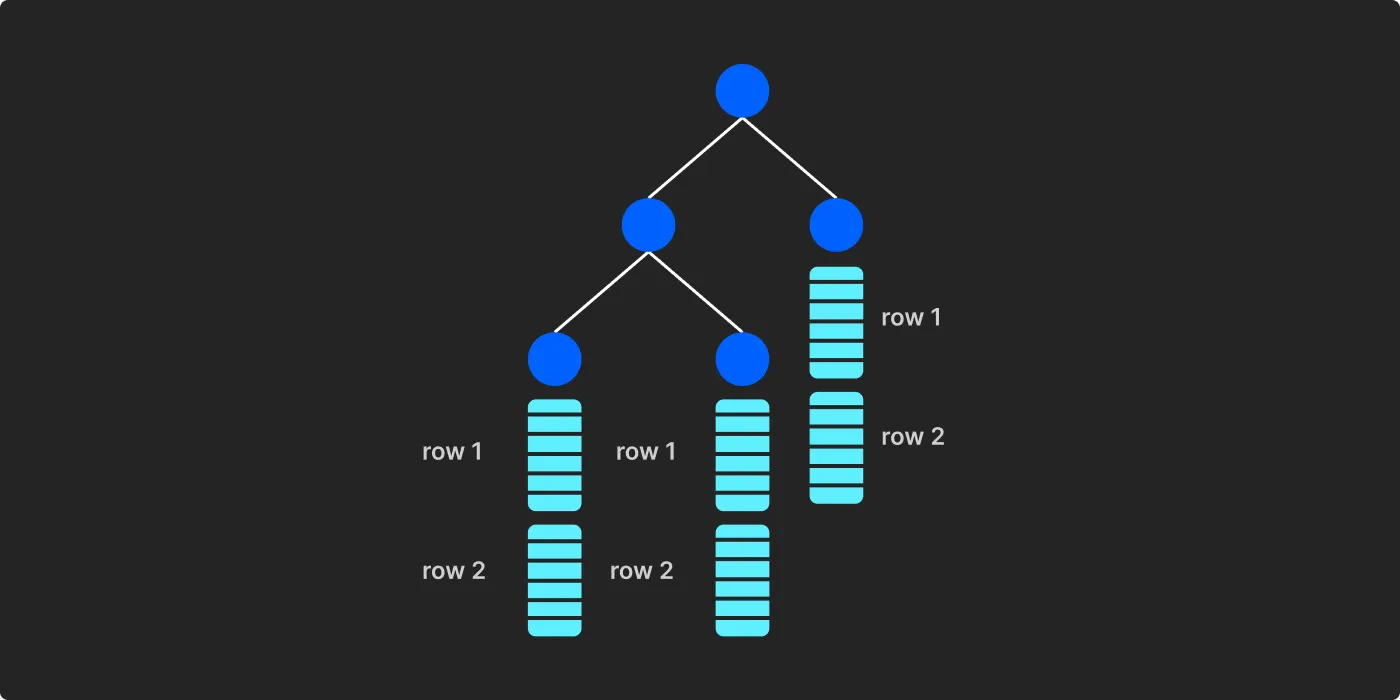
In BigQuery, each node is a VM. A query execution propagates from the root server (node) through intermediate servers to the leaf servers to retrieve the selected columns.
We can modify the query to select individual columns:
SELECT
session_info_1,
session_info_2,
session_info_3,
user_info_1,
user_info_2,
user_info_3,
query_info_1,
query_info_2,
query_info_3,
impression_info_1,
impression_info_2,
impression_info_3,
ts
FROM `project.dataset.table`
WHERE
ts BETWEEN TIMESTAMP("2022-12-01") AND TIMESTAMP("2023-02-28")
AND locale = "US"
LIMIT 100;
Just by selecting all the columns explicitly, I was able to reduce the processed data from 3.08 TB to 2.94TB. That's a 100 GB reduction.
Use Partitioned Table and Query Only Subsets of Data
Google Cloud recommends us to partition tables by date. It lets us query only a subset of data.
To optimize the query further, we can narrow down the date range in the where statement because the table is partitioned by the "ts" column.
SELECT
session_info_1,
session_info_2,
session_info_3,
user_info_1,
user_info_2,
user_info_3,
query_info_1,
query_info_2,
query_info_3,
impression_info_1,
impression_info_2,
impression_info_3,
ts
FROM `project.dataset.table`
WHERE
ts = TIMESTAMP("2022-12-01")
AND locale = "US"
LIMIT 100;
I narrowed down the date range to one day instead of three months. I was able to cut down the processed data to 37.43 GB. It's just a fraction of the original query.
Use Materialized Query Results in Stages
Another way to reduce costs is to reduce the dataset you're querying from. BigQuery offers destination tables to store query results as smaller datasets. Destination tables come with two forms: temporary and permanent. Because temporary tables has a lifetime and it's not designed to be shared and queried, I created a permanent destination table to materialize the query result:
const dataset = bigquery.dataset('materialized_dataset')
const materialzedTable = dataset.table('materialized_table')
// ...
const [job] = await bigquery.createQueryJob({
query: q(locale, '2022-12-01', '2023-02-28', 100),
destination: materialzedTable,
})
The query results will be stored in the destination table. It'll serve as a reference for future queries. Whenever it's possible to query from the destination table, BigQuery will process the data from the table. It'll greatly reduce the data size we look up.
Final Thoughts
It's a very interesting study to reduce the cost in BigQuery. With only three easy steps:
- Don't use *
- Use Partitioned Table and Query Only Subsets of Data
- Use Materialized Query Results in Stages
I was able to reduce the processed data size from 3 TB to 37.5 GB. It reduces the total cost significantly from $3,000 to $30.
If you're interested in learning more about the BigQuery architecture, here're the references that helped me:
- BigQuery explained: An overview of BigQuery's architecture
- A Look at Dremel
- Colossus under the hood: a peek into Google’s scalable storage system
- Jupiter evolving: Reflecting on Google’s data center network transformation
You can read more about BigQuery cost optimizations in the Google Cloud documentation.
Special thanks to Abu Nashir for collaborating with me on the case study and providing valuable insights that helped me understand BigQuery's architecture.
References
- Abu Nashir - LinkedIn
- A Look at Dremel - Peter Goldsborough
- BigQuery - Google Cloud
- BigQuery explained: An overview of BigQuery's architecture - Google Cloud
- Colossus under the hood: a peek into Google’s scalable storage system - Google Cloud
- Column-oriented DBMS - Wikipedia
- Comma-separated values - Wikipedia
- Creating partitioned tables - Google Cloud
- JavaScript modules - MDN
- Jupiter evolving: Reflecting on Google’s data center network transformation - Google Cloud
- Method: jobs.query - Google Cloud
- Protocol_Buffers - Wikipedia
- Run interactive and batch query jobs - Google Cloud
- Using cached query results - Google Cloud
- Writing query results - Google Cloud
Here you have it! Thanks for reading through 🙌 If you find this article useful, please share it to help more people in their engineering journey.
🐦 Feel free to connect with me on twitter!
Ready for the next article? 👉 How to Run A Tech Community in Your Company: An Ex-Principal Engineer’s Guide
Happy coding!